The AI agent ecosystem has rapidly evolved, offering builders a diverse array of frameworks to design, deploy, and scale autonomous systems. From orchestration tools to observability platforms and managed solutions, the choice of framework can significantly impact your project's scalability, reliability, and maintainability. This article synthesizes insights from the latest engineering releases, focusing on frameworks evaluated for multi-agent support, state management, human-in-the-loop capabilities, and enterprise readiness.
Why Framework Selection Matters
Choosing the right AI agent framework is critical for avoiding architectural bottlenecks. Common pitfalls include lack of state persistence, limited observability, and insufficient support for human approval workflows. These issues can lead to costly rewrites or operational failures in production environments. By understanding the strengths and tradeoffs of leading frameworks, builders can make informed decisions tailored to their specific use cases.
Top Frameworks for Orchestration
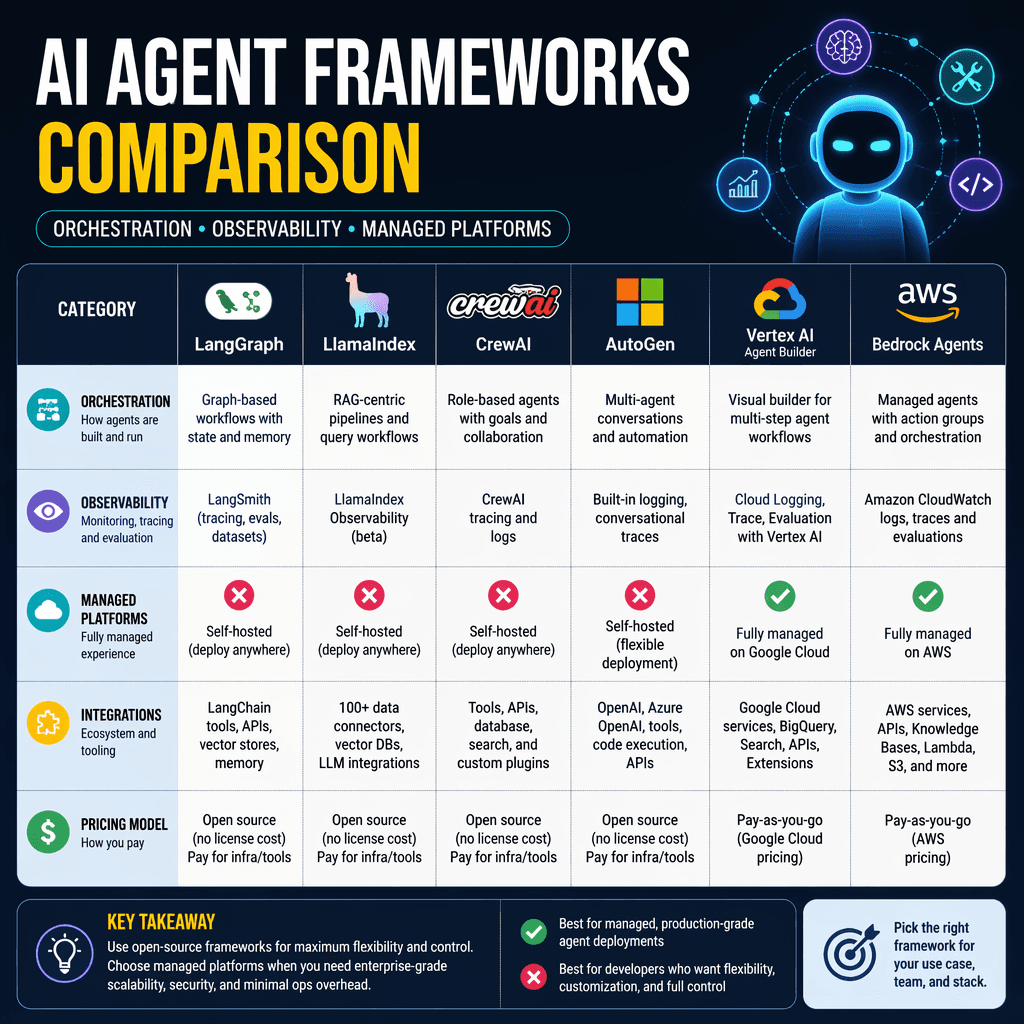
Orchestration frameworks form the backbone of most AI agent systems, handling reasoning, tool selection, execution, and state management. Below are three standout options for different use cases.
Key Takeaways
- LangGraph excels in complex stateful workflows with graph-based orchestration.
- CrewAI simplifies role-based multi-agent collaboration for specialized tasks.
- OpenAI Agents SDK offers robust support for OpenAI-native applications with built-in guardrails.
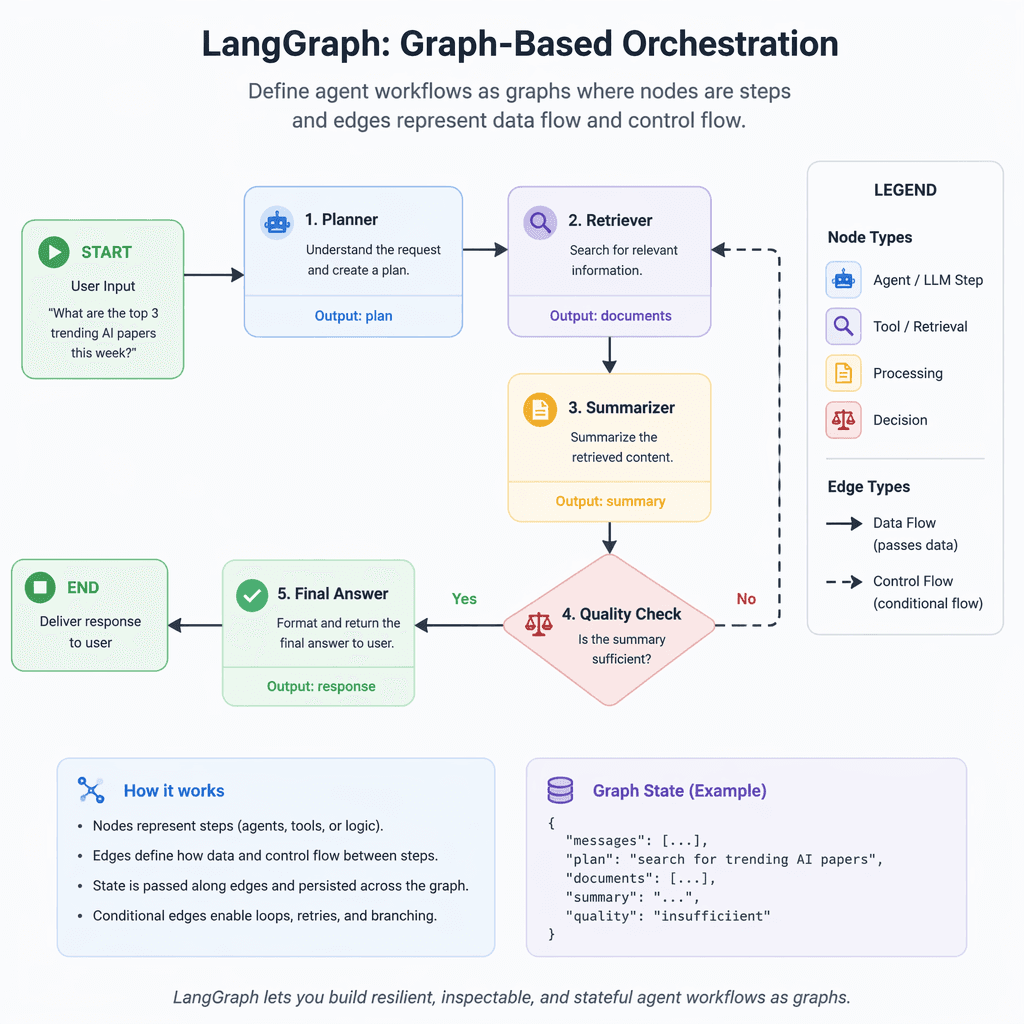
LangGraph: Graph-Based Orchestration
LangGraph extends the LangChain ecosystem by introducing graph-based workflow definitions. Each agent step is represented as a node, with edges controlling data flow and transitions. This architecture is ideal for workflows requiring conditional branching, error recovery, and long-running operations. Key features include state persistence, human-in-the-loop interrupts, and integration with LangSmith for observability. However, its steeper learning curve may deter teams working on simpler single-turn agents.
LangGraph is best suited for multi-step reasoning and workflows requiring state durability.
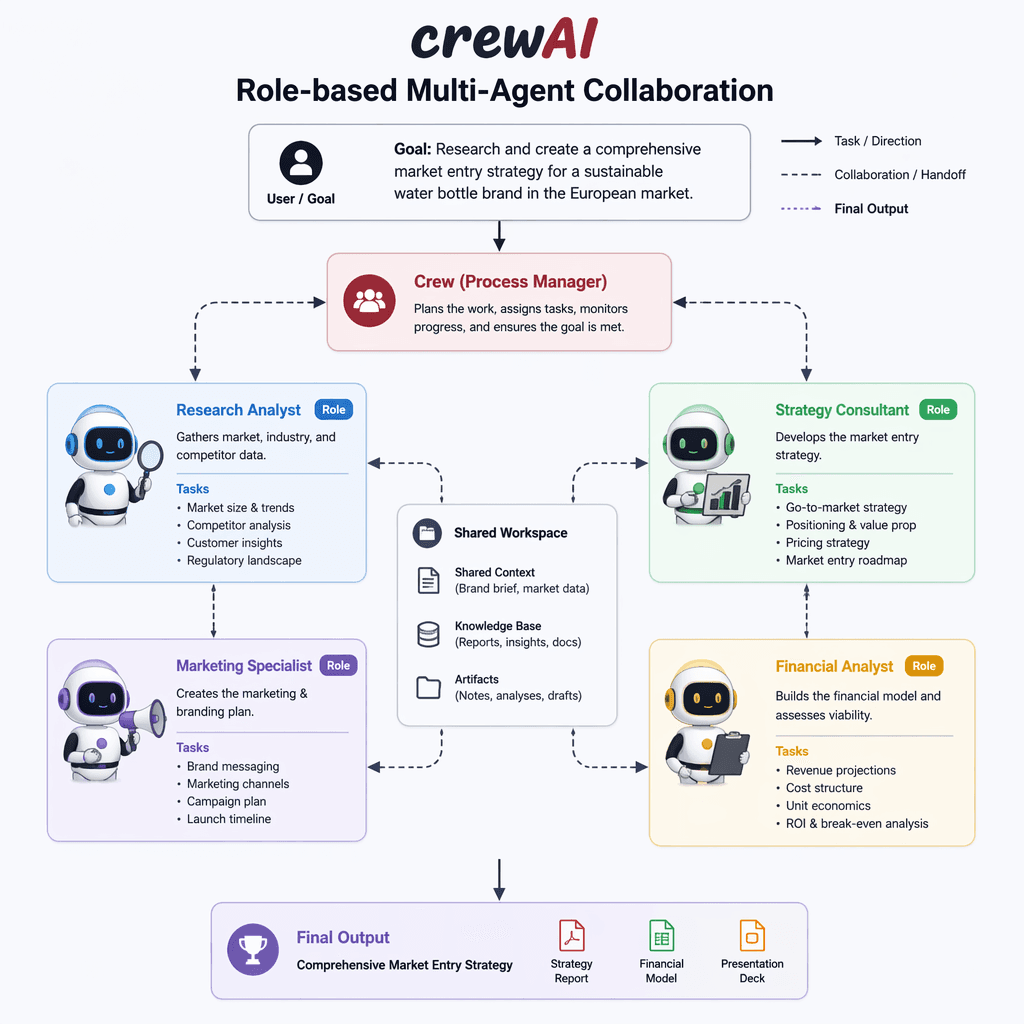
CrewAI: Role-Based Multi-Agent Teams
CrewAI enables builders to define agents with specific roles, goals, and backstories, fostering collaboration among specialized agents. This framework is particularly useful for workflows requiring distinct phases, such as research and content production pipelines. While its role definitions simplify multi-agent coordination, they demand careful prompt engineering to ensure effective task delegation.
Builder note
CrewAI is ideal for teams needing structured collaboration between agents but may be less suitable for workflows requiring granular control over individual agent steps.
OpenAI Agents SDK: OpenAI-Native Production Apps
The OpenAI Agents SDK is optimized for building production applications using OpenAI models. It includes built-in guardrails for input/output validation, multi-agent handoffs, and a tracing dashboard for observability. While it integrates seamlessly with OpenAI's ecosystem, its reliance on proprietary APIs may limit flexibility for teams using alternative providers.
Observability Platforms: Monitoring and Debugging Agents
Observability platforms are essential for debugging and monitoring AI agents in production. LangSmith, Langfuse, and AgentOps stand out for their ability to trace agent workflows, monitor performance, and provide actionable insights. LangSmith is tailored for the LangChain ecosystem, while Langfuse offers open-source monitoring capabilities. AgentOps specializes in agent-specific tracing but comes with proprietary licensing.
Managed Platforms: Full-Stack Agent Infrastructure
For teams seeking end-to-end solutions, managed platforms like Amazon Bedrock Agents and Vertex AI Agent Builder provide comprehensive infrastructure for deploying AI agents. These platforms simplify integration with cloud ecosystems, offering enterprise-grade scalability and security. However, their proprietary nature may lock teams into specific cloud providers.
Source Card
15 Best AI Agent Frameworks for Enterprise: Open-Source to Managed (2026)This source ranks 15 production-ready AI agent frameworks based on orchestration, observability, and managed platform capabilities. It provides a detailed comparison of features, tradeoffs, and enterprise readiness.
blog.premai.io
| Signal | Why it matters |
|---|---|
| Multi-agent support | Enables complex workflows involving multiple specialized agents. |
| State management | Ensures agents can pause, resume, and maintain context across operations. |
| Human-in-the-loop | Allows human intervention for critical decision points. |
| Observability | Facilitates debugging and performance monitoring in production environments. |
- Evaluate your use case: Determine whether you need orchestration, observability, or managed solutions.
- Consider scalability: Choose frameworks that support state persistence and multi-agent workflows.
- Assess ecosystem compatibility: Ensure the framework integrates with your existing tools and platforms.
- Plan for observability: Prioritize frameworks with robust monitoring and debugging capabilities.
- Avoid lock-in risks: Be cautious of proprietary solutions that limit flexibility.
- LangGraph: Best for complex workflows with conditional branching.
- CrewAI: Ideal for role-based collaboration among agents.
- OpenAI Agents SDK: Optimized for OpenAI-native applications.
- LangSmith: Observability tailored for LangChain users.
- Amazon Bedrock Agents: AWS-native managed platform.
- https://blog.premai.io/15-best-ai-agent-frameworks-for-enterprise-open-source-to-managed-2026
Builder implications
For teams evaluating Navigating the Latest AI Agent Frameworks: Engineering Insights for Builders, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from blog.premai.io gives builders a concrete signal to inspect: 15 Best AI Agent Frameworks for Enterprise: Open-Source to Managed (2026). That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI agent frameworks, orchestration tools, observability platforms, managed AI solutions already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.