In 2026, AI agent observability has evolved from a nice-to-have feature into a critical operational necessity. Engineering teams deploying multi-agent systems face increasing pressure to answer two key questions: 'Why did the agent behave this way?' and 'What is the cost of this behavior?' Traditional monitoring tools fall short in addressing these questions, making specialized observability frameworks essential for maintaining control over production systems.
Why Traditional APM Tools Fail for AI Agents
Application Performance Monitoring (APM) tools like Datadog and New Relic excel at tracking latency, error rates, and resource usage. However, these metrics barely scratch the surface of what matters for AI agents. Observability for AI systems must focus on answer quality, reasoning chain consistency, tool call success rates, and token cost attribution. Without these insights, engineering teams risk losing visibility into critical aspects of agent behavior.
Key Takeaways
- Traditional APM tools lack metrics tailored to AI agents.
- Observability must include reasoning chains, tool call flows, and cost attribution.
- LLM-native tools like Langfuse and LangSmith lead in depth and usability.
The Three Pillars of AI Agent Observability
Effective observability for AI agents relies on three foundational pillars: distributed tracing, metrics, and structured logging. Each pillar addresses a unique aspect of system transparency, enabling teams to diagnose issues, optimize performance, and control costs.
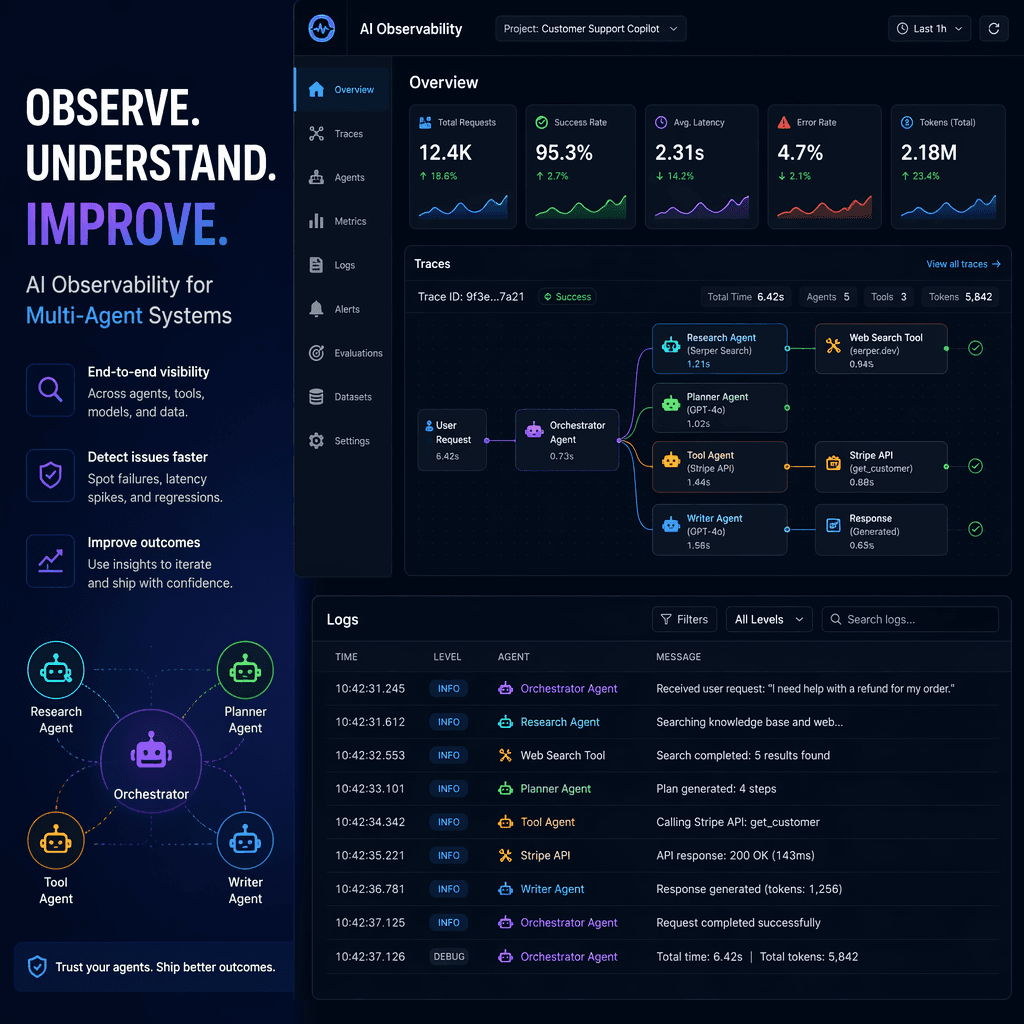
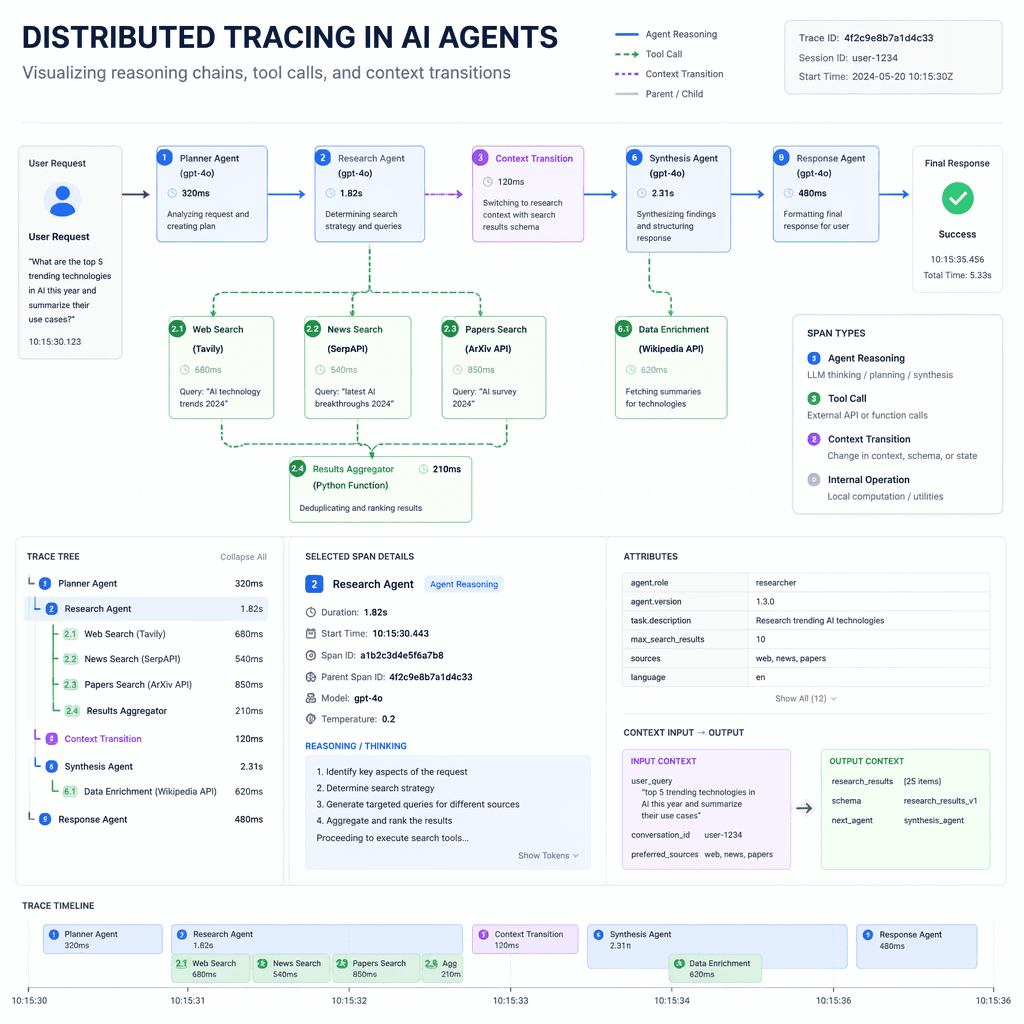
Distributed Tracing
Distributed tracing for AI agents goes beyond measuring function execution times. It reconstructs the decision-making process by capturing input messages, tool call arguments, results, context changes, and final outputs. Tools like OpenTelemetry and Langfuse make it possible to trace multi-agent workflows with precision, enabling engineers to pinpoint the root cause of unexpected behaviors.
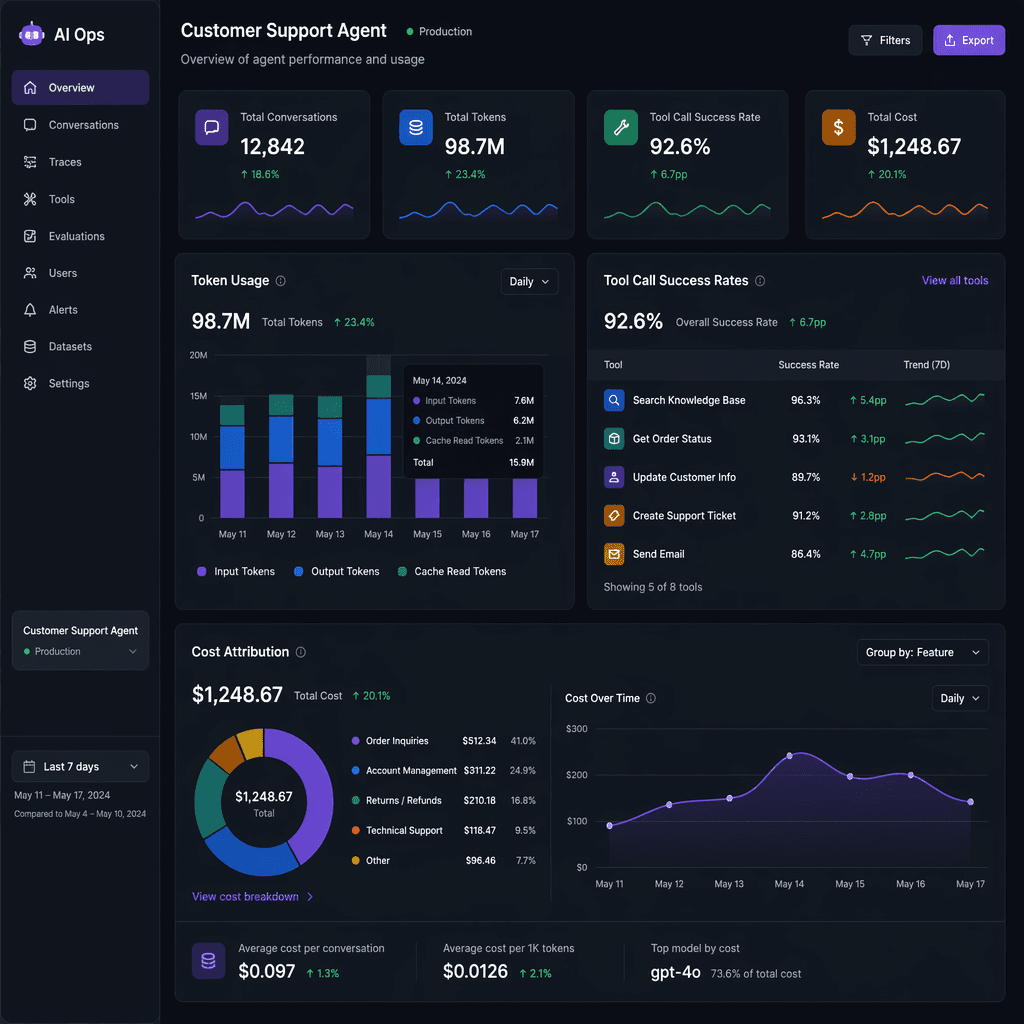
Metrics
Metrics provide quantitative insights into system performance, cost efficiency, and quality. Key metrics include token usage, tool call success rates, retry rates, and user feedback scores. Tracking these metrics allows teams to identify inefficiencies and optimize agent workflows.
Structured Logging
Structured logging ensures reproducibility by capturing detailed records of agent interactions. Logs should include timestamps, trace IDs, agent IDs, tool call details, and cost metrics. This level of detail enables teams to reconstruct incidents and implement targeted fixes.
'Observability is not just about collecting data; it's about making sense of it to drive actionable insights.'
Builder note
When implementing observability, prioritize tools that integrate seamlessly with your existing stack and offer flexibility in data routing. OpenTelemetry is a strong choice for avoiding vendor lock-in.
Source Card
AI Agent Observability in Production: Making Your LLM Systems TransparentThis source provides a practical guide for engineering managers on monitoring multi-agent systems, covering distributed tracing, metrics, and logging.
jangwook.net
Tool Comparison: Choosing the Right Platform
Several platforms offer observability solutions tailored to AI agents. Choosing the right tool depends on your team's priorities, such as data privacy, integration ease, or evaluation capabilities.
| Platform | Best For |
|---|---|
| Langfuse | Teams prioritizing data sovereignty and cost efficiency |
| LangSmith | LangChain-based workflows |
| Braintrust | Prompt optimization and model evaluation |
| Arize AI | Enterprise-scale ML and LLM systems |
| Helicone | Quick setup with minimal code changes |
Real-World Patterns Uncovered by Observability
Observability surfaces patterns that would otherwise remain hidden, such as cost inefficiencies, agent loops, and quality drift. For example, token tracing can reveal unnecessary operations, while span depth monitoring can catch infinite loops between agents. These insights enable proactive fixes and continuous improvement.
- Adjust prompts to reduce token usage and costs.
- Implement circuit breakers to prevent infinite loops.
- Track user feedback to identify quality degradation.
Alert Design: Signals Over Noise
Effective alerting frameworks balance sensitivity and relevance. Critical alerts should trigger immediate responses, while warnings and informational signals can be reviewed during daily or weekly operations. This approach minimizes alert fatigue and ensures focus on high-impact issues.
- Critical: Agent error rate > 10% or cost exceeds budget.
- Warning: Success rate drops > 5% or latency increases significantly.
- Info: Usage pattern shifts or prompt efficiency changes.
Closing Thoughts: Observability as a Core Competency
For engineering teams deploying AI agents, observability is no longer optional. It is a foundational competency that ensures system transparency, cost control, and quality assurance. By adopting robust observability practices, teams can maintain control over complex multi-agent systems and deliver consistent value to users.
- AI Agent Observability in Production: Making Your LLM Systems Transparent - jangwook.net
Builder implications
For teams evaluating Engineering Observability for AI Agents: A Practical Guide, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from jangwook.net gives builders a concrete signal to inspect: AI Agent Observability in Production: Making Your LLM Systems Transparent. That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI observability, LLM monitoring, OpenTelemetry, Langfuse already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.