AI agent frameworks are rapidly evolving, offering engineers and founders new ways to build scalable, autonomous systems. From LangChain’s modular architecture to CrewAI’s collaborative autonomy, each framework brings unique strengths and tradeoffs. This article explores the latest engineering releases, providing actionable insights for selecting the right framework based on your technical stack, use case, and team size.
Why AI Agent Frameworks Matter
AI agents represent the next frontier in automation, capable of understanding goals, taking initiative, and learning from outcomes. For businesses, integrating AI agents can reduce repetitive tasks, accelerate workflows, and unlock entirely new product categories. However, building production-ready systems requires frameworks that align with your architecture, compliance needs, and scalability goals.
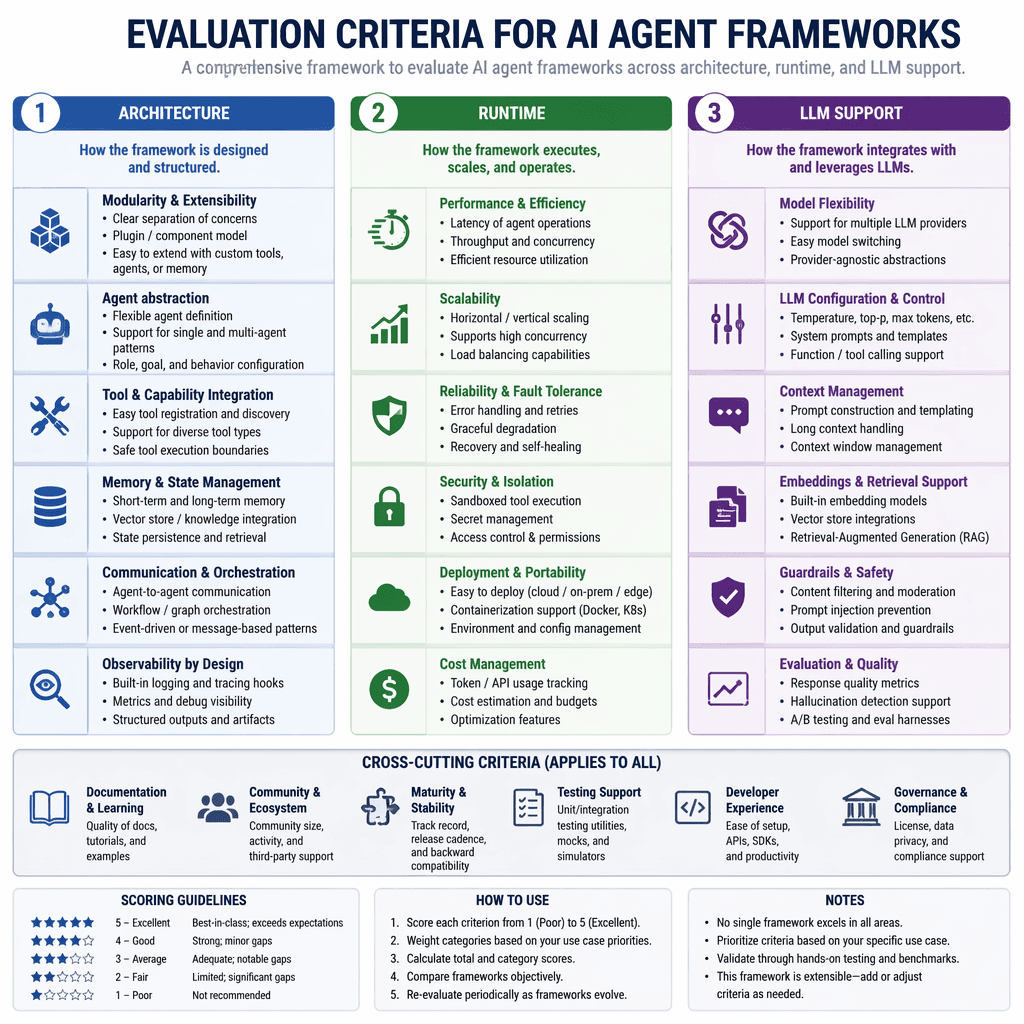
Evaluation Criteria for AI Agent Frameworks
To make informed decisions, engineers must evaluate frameworks across key dimensions: architecture, language support, extensibility, runtime environment, LLM backend compatibility, and community maturity. These criteria ensure the chosen framework can handle your specific requirements, whether it’s multi-agent orchestration, fine-tuning proprietary models, or integrating with enterprise systems.
| Signal | Why it matters |
|---|---|
| Architecture | Defines modularity, memory handling, and orchestration capabilities. |
| Language Support | Ensures compatibility with your team’s coding expertise. |
| Extensibility | Allows customization and integration with third-party tools. |
| Runtime Environment | Supports single-agent, multi-agent, or distributed workflows. |
| LLM Backend Support | Determines model flexibility and deployment options. |
| Community Maturity | Indicates production readiness and developer resources. |
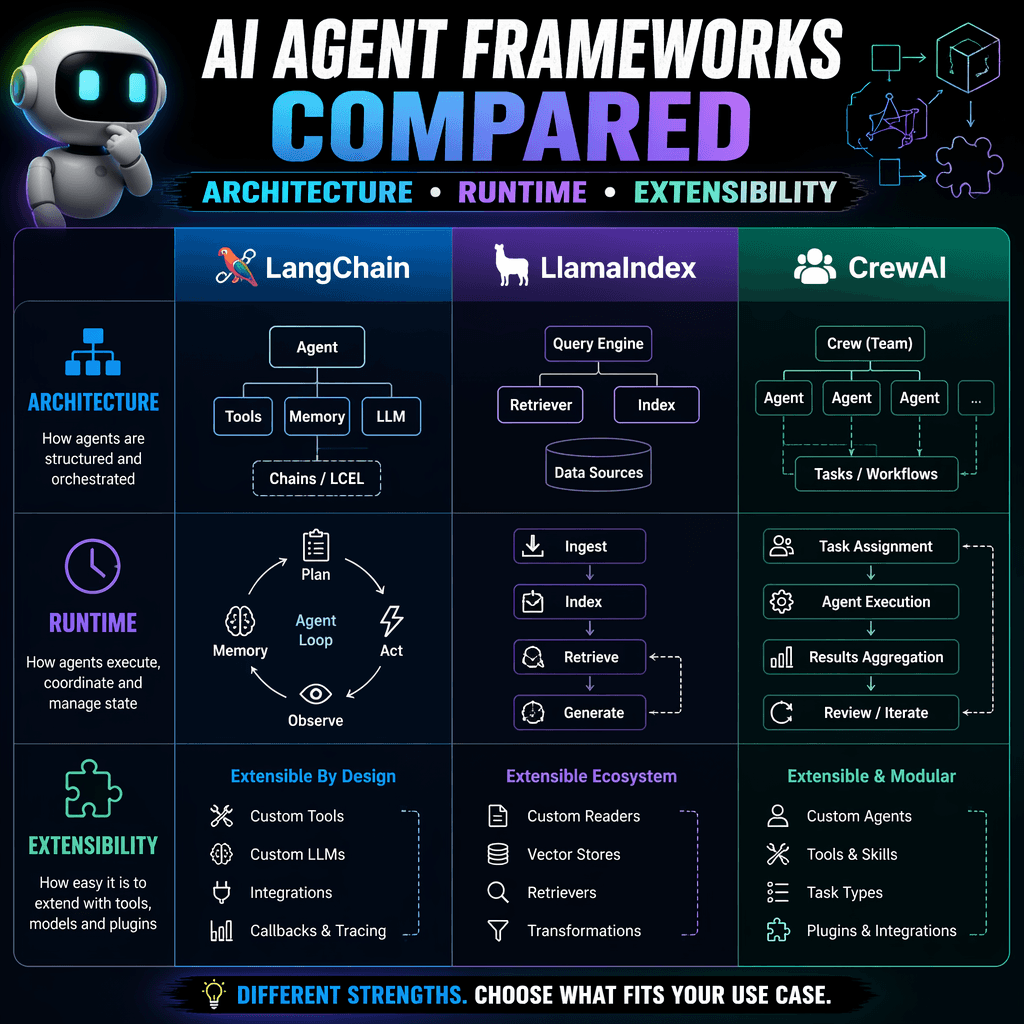
Framework Highlights: LangChain, LangGraph, CrewAI, and More
Each framework excels in specific areas, making them suitable for different use cases. Below are detailed insights into four standout frameworks: LangChain, LangGraph, CrewAI, and AutoGen.
LangChain: Modular and Transparent
LangChain is a popular choice for building advanced AI agents, offering modular components for connecting prompts, APIs, and reasoning steps. Its transparent logic flow is ideal for debugging and compliance, while its extensive ecosystem supports integrations with major LLMs and vector databases. However, its complexity makes it less suitable for quick automations or small-scale tasks.
Key Takeaways
- Best for traceability and structured workflows.
- Ideal for enterprise systems requiring compliance and debugging.
- Heavy setup overhead for smaller projects.
LangChain excels in environments where traceability and control are critical, such as regulated industries or structured workflows.
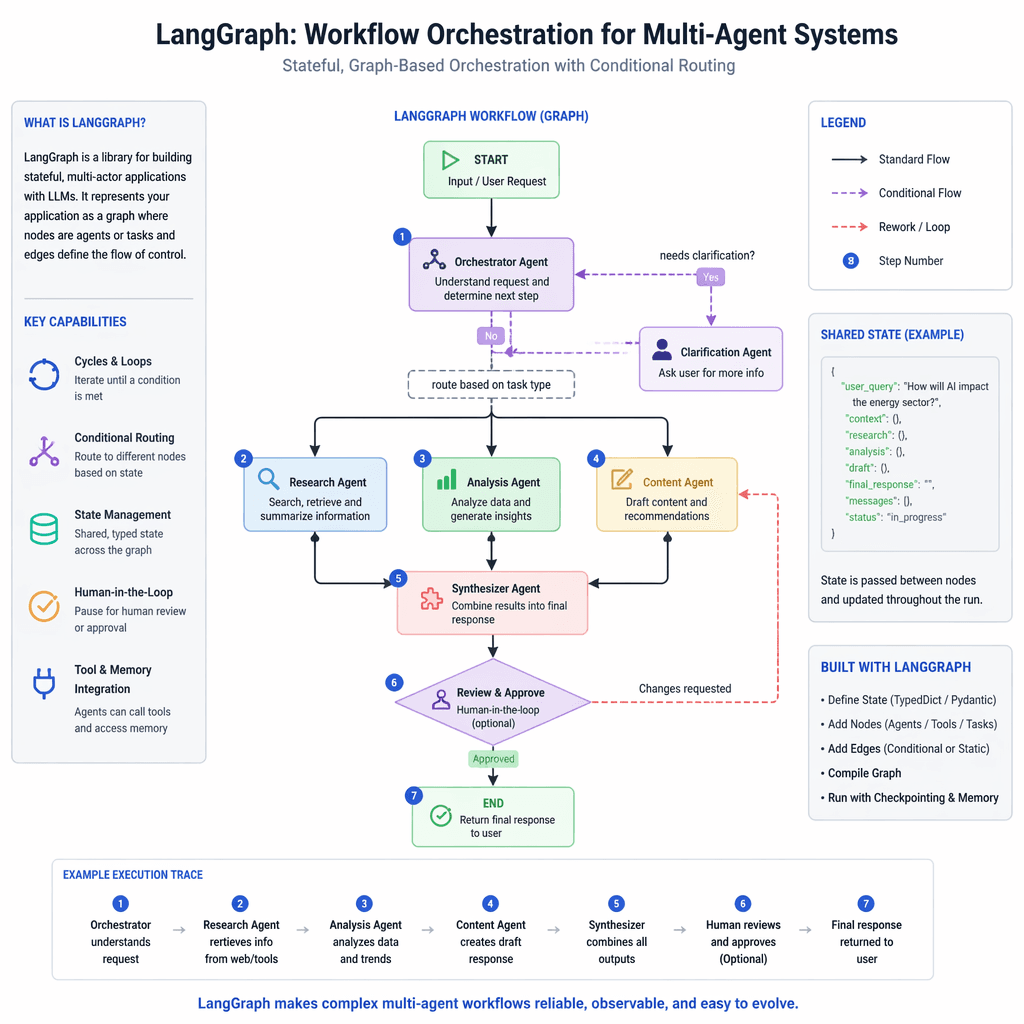
LangGraph: Visual Workflow Management
LangGraph builds on LangChain by adding a visual layer for representing workflows as directed graphs. This makes it easier to debug and scale multi-agent systems. While its graph-based approach simplifies complex processes, its limited documentation and experimental features pose challenges for adoption.
Builder note
LangGraph is ideal for orchestrating complex workflows where visual monitoring and parallelization are priorities. Consider it for multi-agent systems requiring transparency.
CrewAI: Collaborative Autonomy
CrewAI focuses on collaborative autonomy, enabling agents to delegate tasks, share updates, and coordinate results like a real team. Its role-based structure simplifies workflows but requires careful tuning to ensure reliability in long-running tasks. Sparse documentation and monitoring challenges are notable drawbacks.
- Best for team-like dynamics in experimental pipelines.
- Requires robust monitoring tools for multi-agent interactions.
- Extensible with custom APIs and modules.
AutoGen: Conversational Orchestration
AutoGen, developed by Microsoft Research, specializes in conversational orchestration, making it ideal for simulation-heavy tasks and multi-agent reasoning experiments. Its strong research foundation and seamless agent communication are strengths, but its Python-heavy configuration and slower production deployment make it less suitable for fast-paced projects.
Source Card
14 AI Agent Frameworks Compared: LangChain, LangGraph, CrewAI, OpenAI ...This source provides a detailed comparison of 14 AI agent frameworks, offering insights into architecture, extensibility, runtime, and use case recommendations.
Softcery
Adoption Guidance for Engineers and Founders
- Define your use case: Determine whether you need single-agent workflows, multi-agent orchestration, or distributed systems.
- Evaluate technical stack compatibility: Ensure the framework supports your team’s preferred languages and tools.
- Prioritize extensibility: Look for frameworks that allow custom integrations and plugins.
- Consider runtime requirements: Choose synchronous, asynchronous, or event-driven models based on task complexity.
- Assess community maturity: Opt for frameworks with active development and robust documentation.
Key Risks and Tradeoffs
While AI agent frameworks offer powerful capabilities, they come with risks. Complex setups can lead to debugging challenges, and experimental features may require workarounds. Additionally, frameworks with sparse documentation can slow adoption, especially for smaller teams.
- Softcery’s comparison of AI agent frameworks: https://softcery.com/lab/top-14-ai-agent-frameworks-of-2025-a-founders-guide-to-building-smarter-systems
Builder implications
For teams evaluating Comparing AI Agent Frameworks: Engineering Insights for Builders, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from softcery.com gives builders a concrete signal to inspect: 14 AI Agent Frameworks Compared: LangChain, LangGraph, CrewAI, OpenAI .... That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI agent frameworks, LangChain, multi-agent systems, engineering tools already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.