OpenAI's Responses API has long been the backbone of agentic workflows, enabling models like Codex to perform iterative tasks such as debugging code, running tests, and applying fixes. However, as model inference speeds increased dramatically with the launch of GPT-5.3-Codex-Spark, the API itself became a bottleneck. Engineers at OpenAI tackled this challenge by introducing WebSockets, a persistent connection protocol that reduced API overhead and improved latency by 40%. This article explores the technical innovations behind this shift and provides practical guidance for builders integrating WebSocket-based workflows.
Understanding the Bottleneck
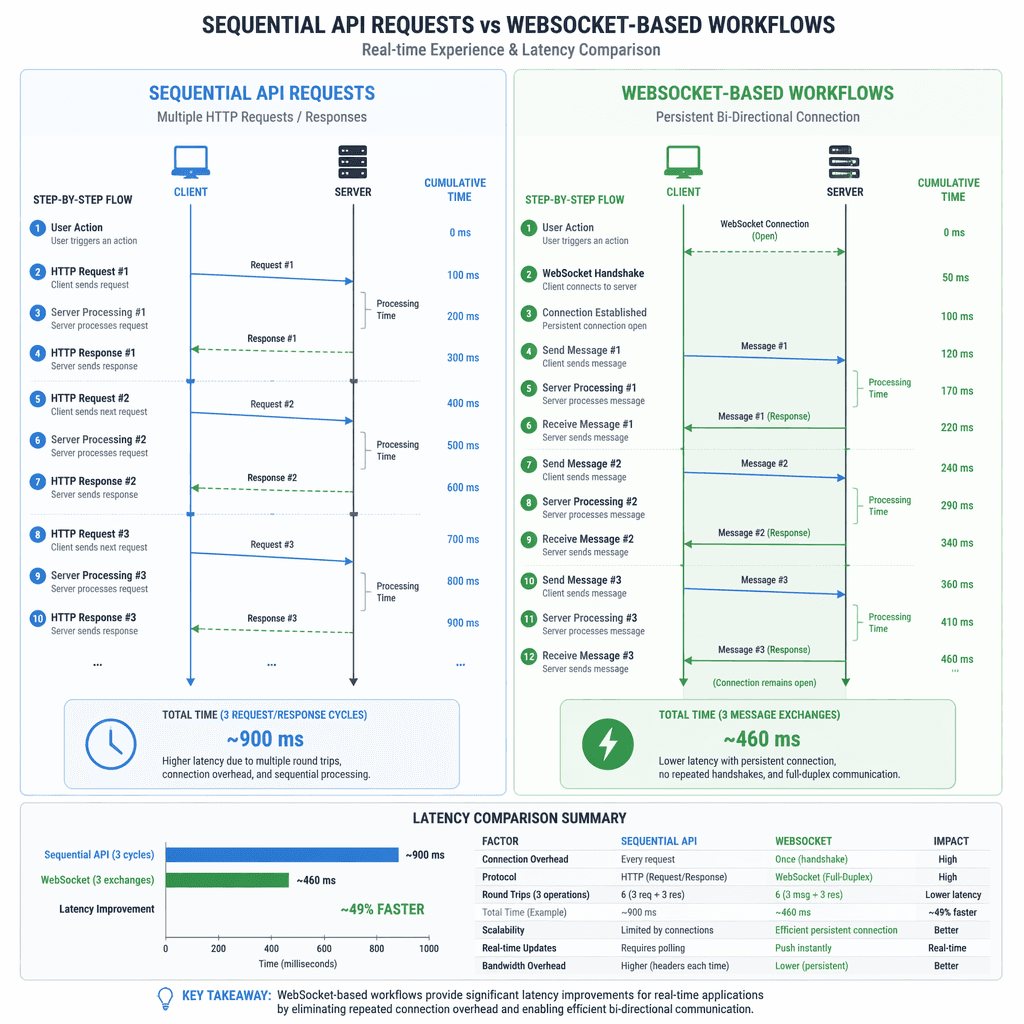
Historically, API service overhead was overshadowed by the slower inference speeds of earlier models like GPT-5 and GPT-5.2, which operated at 65 tokens per second (TPS). With GPT-5.3-Codex-Spark achieving speeds of over 1,000 TPS on specialized Cerebras hardware, the inefficiencies in the API became glaring. Each agentic workflow involved multiple back-and-forth API calls, processing redundant context and conversation history, which compounded latency as tasks grew more complex.
Optimizing for Speed: Initial Improvements
OpenAI began by optimizing critical-path latency for single requests. Key improvements included caching rendered tokens and model configurations in memory, reducing network hops by bypassing intermediate services, and streamlining safety classifiers to flag issues faster. These changes improved time-to-first-token (TTFT) by 45%, enhancing responsiveness. However, these optimizations were insufficient to fully leverage the speed of GPT-5.3-Codex-Spark, as the structural inefficiencies of treating each request independently persisted.
Introducing Persistent Connections with WebSockets
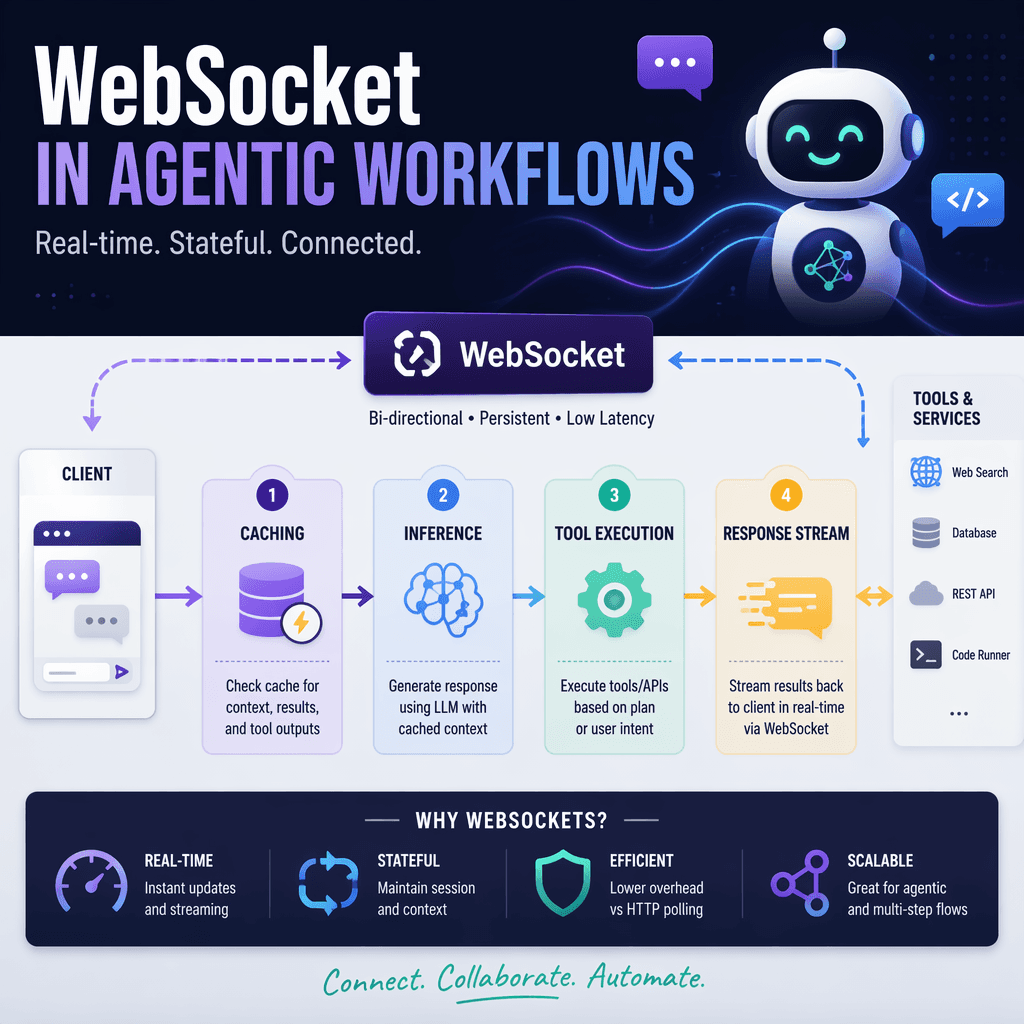
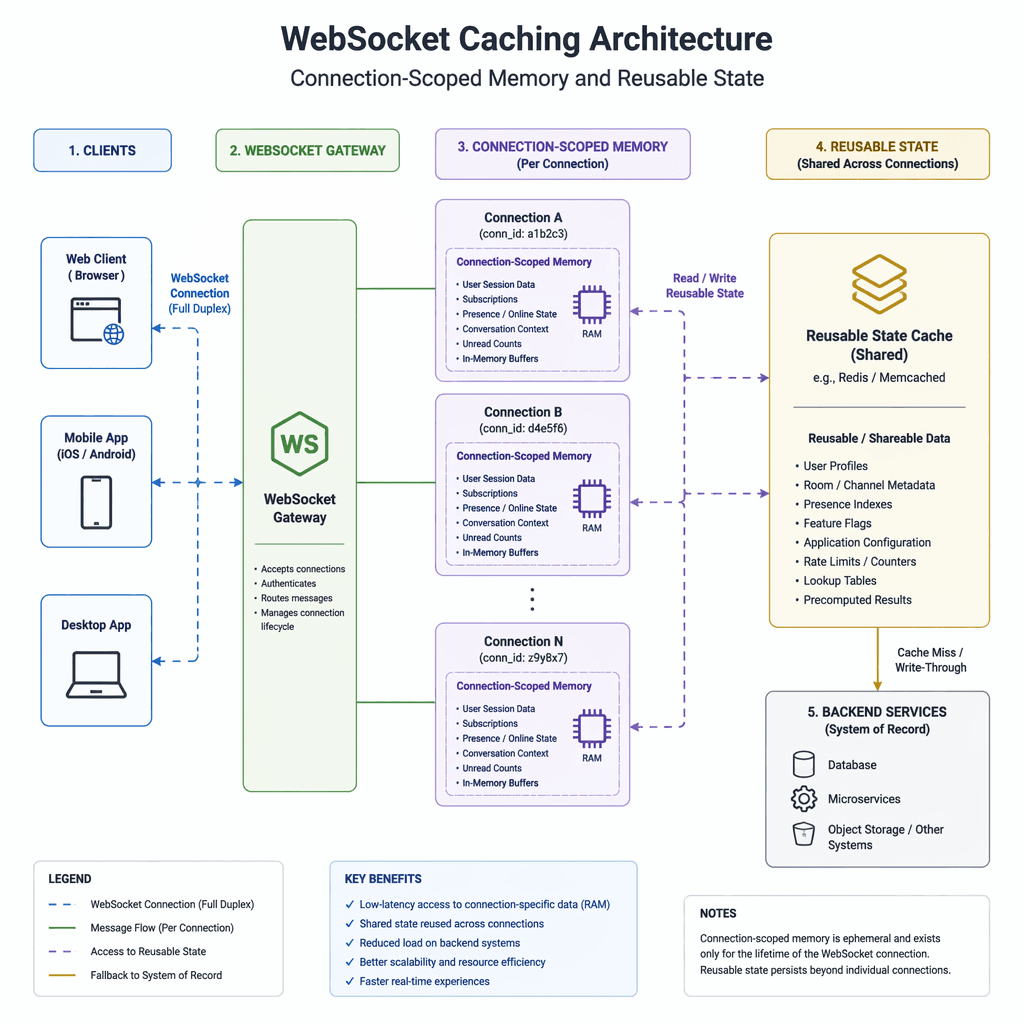
To address the structural inefficiencies, OpenAI explored persistent connection protocols such as WebSockets and gRPC bidirectional streaming. WebSockets emerged as the preferred choice due to its simplicity and compatibility with existing API input and output shapes. By maintaining a persistent connection, reusable context and state could be cached in memory, eliminating redundant processing for follow-up requests.
The WebSocket prototype redefined latency expectations. Using `asyncio`, the Responses API asynchronously blocked in the sampling loop after a tool call, sending a `response.done` event to the client. The client executed the tool call and returned a `response.append` event with the result, unblocking the sampling loop and allowing the model to continue. This approach minimized repeated API work, enabling preinference and postinference tasks to be performed only once per agent rollout.
Key Takeaways
- WebSockets reduced API overhead by enabling persistent connections and caching reusable state.
- Caching prior responses, tool definitions, and sampling artifacts eliminated redundant processing.
- The WebSocket prototype achieved near-minimal latency but required careful design to maintain API familiarity.
The WebSocket prototype changed what we thought was possible for Responses API latency, enabling agentic workflows to scale with the speed of GPT-5.3-Codex-Spark.
Builder note
When integrating WebSockets, ensure your infrastructure supports persistent connections and memory caching. Test for edge cases where connection state might be lost or corrupted.
Source Card
Speeding up agentic workflows with WebSockets in the Responses APIThis source provides a detailed look at how WebSockets and caching improved latency in agentic workflows, enabling faster model interactions.
OpenAI
| Signal | Why it matters |
|---|---|
| WebSocket integration | Reduced API overhead and improved latency by 40%. |
| Caching reusable state | Eliminated redundant processing for follow-up requests. |
| Safety stack optimizations | Enabled faster flagging of issues during agentic workflows. |
Balancing Familiarity and Performance
To ensure developers could adopt WebSocket mode without significant rewrites, OpenAI retained the familiar API shape. Developers continued using `response.create` with the same body, adding `previous_response_id` to reference cached state. The server maintained an in-memory cache scoped to the connection, storing prior responses, tool definitions, and sampling artifacts. This design struck a balance between minimal latency and ease of integration.
- Use `response.create` with `previous_response_id` to leverage cached state.
- Ensure your client supports persistent WebSocket connections.
- Test for edge cases where connection state might be lost or corrupted.
Adoption Results and Lessons Learned
During the alpha phase, key coding agent startups integrated WebSocket mode into their infrastructure, reporting up to 40% improvements in agentic workflows. The launch saw widespread adoption, with Codex ramping up the majority of Responses API traffic onto WebSocket mode. This transition unlocked the full speed of GPT-5.3-Codex-Spark, achieving bursts of up to 4,000 TPS.
- WebSocket mode enabled faster and more efficient agentic workflows.
- Caching reusable state reduced redundant processing and improved latency.
- Developers appreciated the familiar API shape, easing adoption.
- https://openai.com/index/speeding-up-agentic-workflows-with-websockets
Builder implications
For teams evaluating Accelerating Agentic Workflows with WebSockets in OpenAI's Responses API, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from openai.com gives builders a concrete signal to inspect: Speeding up agentic workflows with WebSockets in the Responses API - OpenAI. That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where WebSockets, Responses API, Codex, GPT-5.3 already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.