
Most teams do not discover that their agent is unobservable during a demo. They discover it during the first production incident, when a user asks why the agent deleted the wrong record, called the wrong tool, or gave an answer that looked confident but came from stale context. At that moment, plain application logs are not enough. You need a replayable account of the run: what the user asked, what context was retrieved, which tools were considered, which tool was called, what the model saw, what the model returned, and which guardrails intervened.
The Real Production Problem
Observable agent systems treat every run like a small distributed system. A single request can fan out into retrieval, planning, tool execution, permission checks, retries, human approval, evaluator passes, and final response synthesis. Any one of those steps can be correct in isolation while the overall answer is wrong. That is why observability for agents has to be designed around causality, not just uptime. The question is not only whether the API returned 200. The question is whether the agent followed the intended path, used the right evidence, respected policy, and stopped when uncertainty was high.
Key Takeaways
- Give every agent run a durable run ID, then attach step IDs, tool IDs, model IDs, policy decisions, and retrieval IDs to that same trace.
- Separate diagnostic payloads from user data so you can debug incidents without spreading sensitive information across logs.
- Measure agent quality with outcome metrics, not only latency and error rate. Track task completion, escalation, correction, refusal, and retry loops.
- Build a replay path before you need one. The fastest incident response is a run timeline that explains the decision chain without guessing.
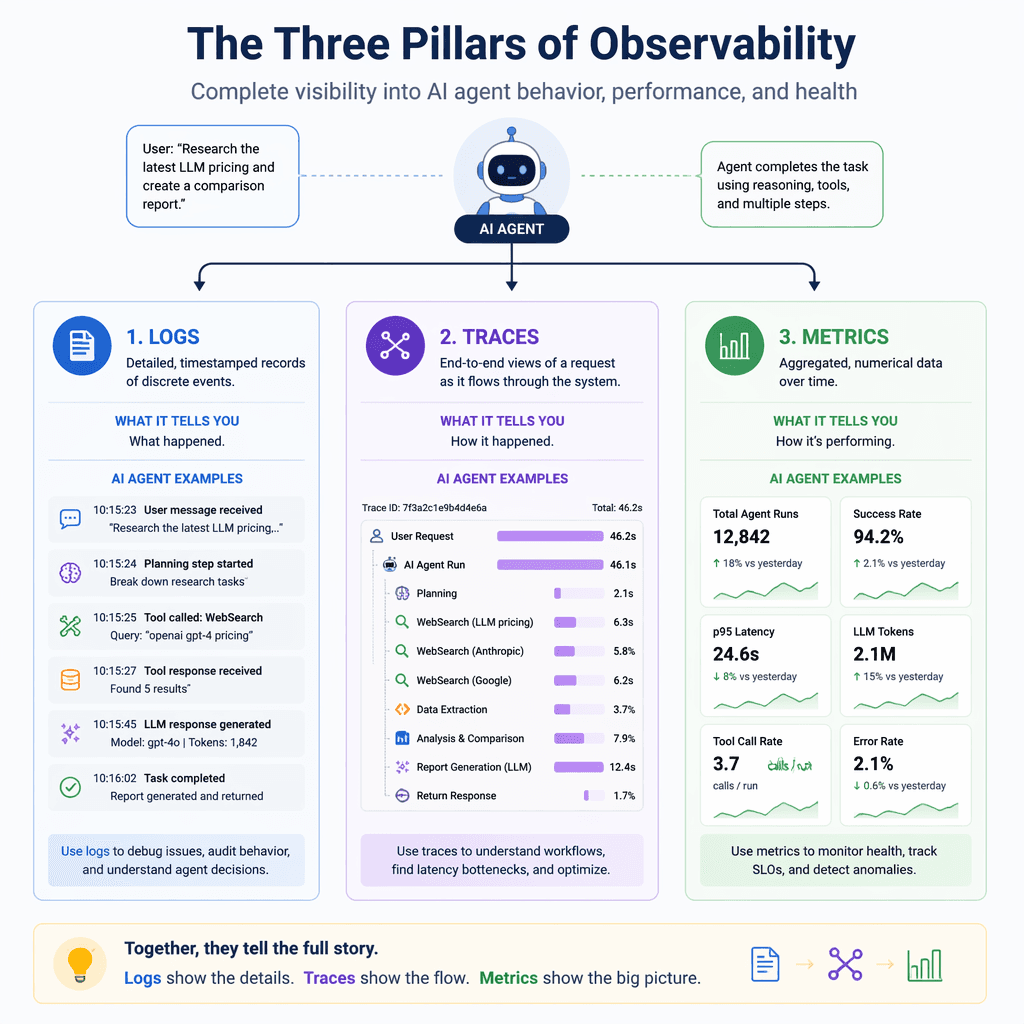
The Observability Contract
The most useful mental model is an observability contract. Before an agent reaches production, decide which facts every run must emit. The contract should be stable enough that engineers, support, product, and safety reviewers can all inspect the same run and arrive at the same story. For a customer-support agent, that might mean conversation ID, account tier, retrieved policy docs, tool calls, confidence score, handoff reason, and final resolution. For a coding agent, it might mean repository, branch, files touched, tests run, commands executed, failures, and reviewer comments. The exact fields change by product, but the shape stays the same: identity, context, action, outcome, and review.
| Signal | What to capture | Why it matters |
|---|---|---|
| Run identity | run_id, session_id, user_id hash, tenant_id hash, surface | Lets every event join back to one timeline without exposing raw personal data. |
| Model decision | model, deployment, prompt version, tool choice, confidence, refusal state | Shows whether failures came from model behavior, prompt drift, or routing. |
| Context path | retrieval query, document IDs, memory IDs, freshness, citation URLs | Explains why the agent believed a claim and whether the evidence was stale. |
| Tool execution | tool name, input schema version, status, latency, retry count, sanitized output size | Turns black-box tool use into debuggable operations data. |
| Outcome | completion, escalation, correction, user rating, evaluator score, incident flag | Connects technical traces to whether the agent actually helped. |
Builder note
Do not wait for a perfect telemetry system. Start with one run timeline that captures planning, retrieval, tool calls, and final answer. Add richer metrics after the team can already explain a failed run from beginning to end.
What To Log Without Creating A Data Problem
Agent logs are risky because the most useful debugging fields are often the fields you should least want scattered through observability tools. Raw prompts can contain customer secrets. Tool inputs can contain account details. Retrieved documents can contain private contracts. The answer is not to log nothing. The answer is to log structured, sanitized facts by default and keep high-risk payloads behind stricter retention, access control, and redaction. A production system should let an engineer know that the agent called the billing tool with schema version 4 and received a validation error, without exposing the full customer invoice in every log line.
- Log stable IDs and hashes first: run ID, trace ID, prompt version, document IDs, tool names, and policy IDs.
- Log sizes and statuses instead of raw payloads when possible: token count, document count, output byte length, validation status, and error class.
- Store sensitive prompt and tool payloads in a protected debug store with short retention, scoped access, and audit trails.
- Attach every retry to the original step ID so a loop does not look like separate unrelated failures.
- Capture the final answer and cited source IDs together so quality review can check whether the response was grounded.
- Mark synthetic test runs, internal staff runs, and real customer runs differently so metrics are not polluted.
Trace The Agent Like A Workflow, Not A Chatbot
The trace should read like a workflow graph. A planner span starts the run. Retrieval spans show which knowledge sources were queried. Tool spans show external actions. Guardrail spans show allow, block, redact, or escalate decisions. Evaluator spans show whether the answer passed quality checks before the user saw it. This structure matters because agent failures usually cross boundaries. A hallucinated answer may start as a retrieval miss, become a weak planner choice, then survive because no evaluator checked source coverage. If those events live in separate dashboards, the team will debug symptoms. If they live in one trace, the team can fix the cause.
The goal is not more logs. The goal is a run timeline that lets a builder answer what happened, why it happened, and what should change next.
Metrics That Actually Tell You If The Agent Is Healthy
Classic service metrics still matter. Latency, uptime, error rate, and token cost belong on the dashboard. But they are incomplete for agents. A fast agent that confidently completes the wrong task is not healthy. A slow agent that escalates correctly may be doing the right thing. Add product-quality metrics that reflect user outcomes and operational risk. Track how often the agent completes a task without human help, how often users correct it, how often it refuses, how often it calls expensive tools, how often it loops, and how often an evaluator flags unsupported claims. Those metrics let you decide whether the agent is improving or merely staying online.
| Metric | Healthy direction | What it catches |
|---|---|---|
| Task completion rate | Up, with stable quality | Whether users are getting the job done. |
| Unsupported answer rate | Down | Responses that lack enough source evidence. |
| Tool retry rate | Down | Schema drift, brittle integrations, or planner confusion. |
| Escalation quality | Up | Whether the agent knows when to hand off. |
| Cost per successful task | Down or stable | Prompt bloat, excessive retrieval, and runaway loops. |
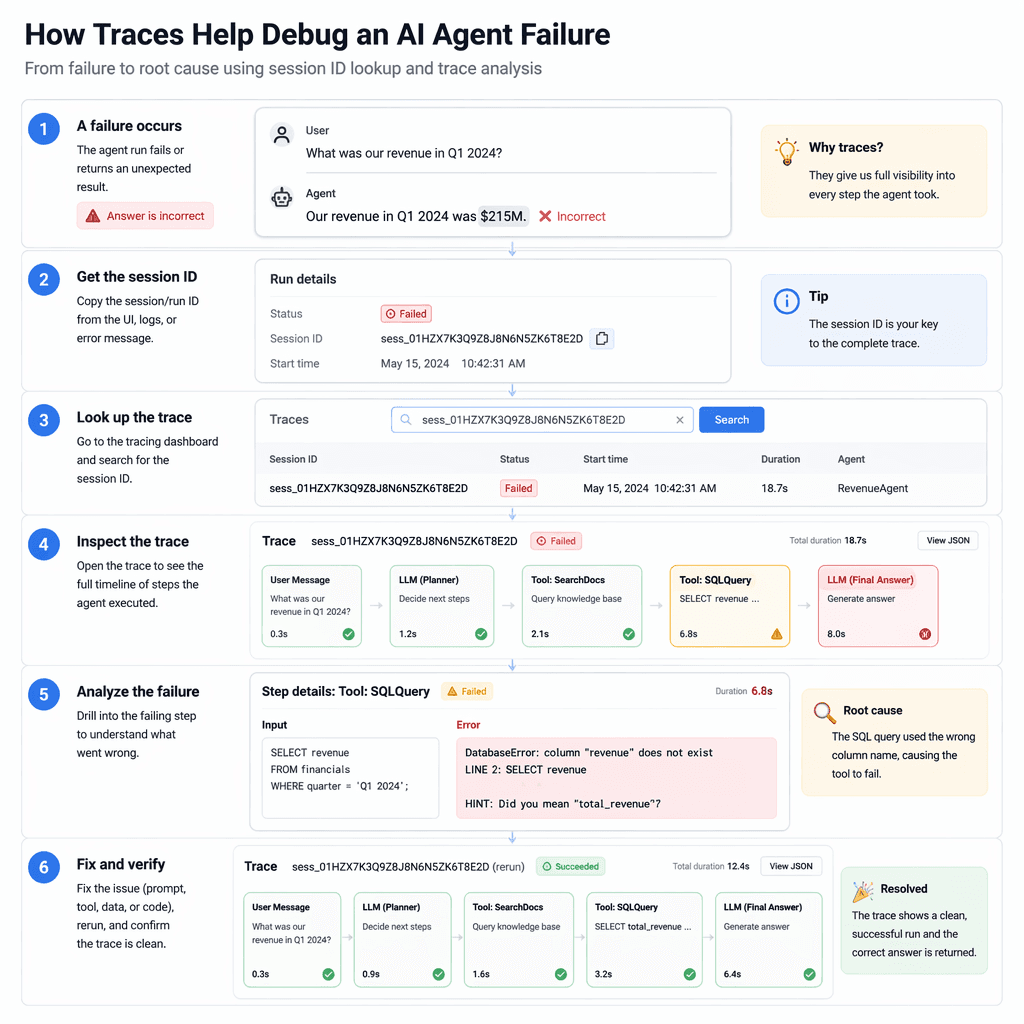
A Practical Incident Triage Flow
When a bad run is reported, the team should not start by reading code or guessing at prompts. Start with the trace. Confirm the user-visible failure, then walk backward through outcome, evaluator, final answer, tool calls, retrieval, and planner state. The point is to classify the failure before fixing it. Was the source missing? Was the source present but ignored? Did the planner choose the wrong tool? Did the tool return an error that the agent hid? Did a guardrail fire too late? Each class has a different fix. Without this triage discipline, teams patch prompts for infrastructure bugs and patch tools for product-policy gaps.
- Open the run timeline and confirm the exact answer or action the user saw.
- Check whether the final answer cited the right source IDs and whether those sources were fresh enough.
- Review tool spans for validation errors, timeouts, retries, permission denials, and unexpected output size.
- Inspect evaluator and guardrail spans to see whether the system detected the risk but failed to act.
- Classify the root cause as retrieval, planning, tool execution, policy, model behavior, or product requirement.
- Ship the fix with a regression test that replays the run class, not only the exact user prompt.
Source Card
Building Observable AI Agents: Implementing Logging, Tracing, and Monitoring for Production ReliabilityThe source article is useful because it frames observability as a production reliability requirement for AI agents, not as a nice-to-have logging layer. Agent Mag extends that idea into an operating model for builders shipping agent workflows.
Harness Engineering Academy
The Rollout Plan
A good v1 does not need a giant observability platform. It needs a durable trace schema, a few high-signal metrics, and a habit of reviewing real runs every week. Start with the most valuable production path, not every possible agent feature. Add run IDs and spans. Redact sensitive payloads. Build a dashboard for task completion, unsupported answers, tool failures, and cost per successful task. Then review the worst twenty runs every week and turn the findings into evals, prompt changes, retrieval improvements, and tool contract fixes. That loop is where observability becomes product velocity.
- Week 1: define the trace schema and add run IDs across planner, retrieval, tools, guardrails, and final answer.
- Week 2: add dashboards for task completion, unsupported answers, tool failure rate, loop rate, and cost per successful task.
- Week 3: add replay and regression tests for the top incident classes.
- Week 4: review real production runs with engineering, product, and support, then tune the agent from evidence instead of opinions.
Bottom line
If an agent can take action, it needs a trace. If it can use private context, it needs redaction. If it can fail in subtle ways, it needs outcome metrics. Observability is the difference between a flashy demo and a system a team can responsibly improve.
- https://harnessengineering.academy/blog/building-observable-ai-agents-implementing-logging-tracing-and-monitoring-for-production-reliability